
Data Analysis
Anything you can conceptualize, we can do. Or you can just dump data on us with no idea of what to do with it. We will know!
Bioinformatic Analysis
Any type of -omics analysis, from any stage of data: off-machine to previously analyzed next generation sequencing, long reads, proteomics. . . We can analyze anything with seq or omics in the name. Examples of needed services include:
Bulk RNA-seq processing and differential expression
Mass-spec proteome correlation with subject information
Isoform and variant detection
Disease marker discovery
non-coding RNA analysis
metagenome analysis with subject information




Functional Analysis
Data Integration
Statistical Analysis
Functional, structural, and regulatory analysis of supplied gene lists. For example:
analysis using a composite of > 300 annotation databases (BBID, Biocarta, BRENDA/Enzyme Commission, Ensembl, Gene Cards, gene ontologies, GeneWiki, InterPro, KEGG, MGI, Panther, PathwayCommons, Reactome, SMART)
small read functional exploration: micro-RNA (miRNA), PIWI-interacting RNA (piRNA), circular RNA (circRNA), small nucleolar RNA (snoRNA)
gene content comparison (Anvi'o, PhyloSift)
bacterial community and functional network analysis (Anvi'o, COG, EggNOG, FAPROTAX, HMMER, KEGG, MetaBAT, MetaCyc, PhyloSift, PICRUSt, SPAdes, STRING)
Integration of data from disparate sources: clinical data, laboratory data, imaging data, omics data, previously published datasets, text data. . . We will integrate anything and everything for you. Examples of needed services include:
Integration of unstructured and semi-structured subject information from different databases into a uniform matrix
Geographically based integration of patient records with health and social determinants of health measures (BRFSS, COVID re-imbursements, PLACES/500 Cities, SDOH, SVI)
Combination of immunohistochemical data and MRI-based three dimensional models of brain structures
Statistics performed on a large scale. We primarily use Python and Linux, with integration of R libraries in Python as needed. We can also design and implement custom approaches. Examples of needed services include:
Rank-based (nonparametric) or regression comparisons across gene expression and subject factors (generalized linear models (GLMs), Kruskal Wallis, Mann Whitney U)
Correlation analysis of gene expression with gene expression or with subject clinical factors (Pearson R, Spearman rho)
Unsupervised machine learning to cluster, group, factor reduce, and visualize data while examining multicollinearity (agglomerative hierarchical clustering, Gaussian mixture models, principal component analysis (PCA), t-stochastic neighbor embedding (t-SNE))
Advanced Analytics
Further exploration into your data or literature can require additional computational models or hand curation of external datasets and published findings.
Machine Learning
Most of our analyses include unsupervised machine learning. Further exploration into supervised models, graph machine learning, genetic algorithms, and natural language processing can be helpful for some projects. Additionally, some clients have an expressed desire to include these. We can design an analysis around such methods, or embed them in your project.


Literature Review
Part of any analysis is review of the literature on disease, function, genes, or species highlighted in the study. We can perform a deep dive on available literature and deliver that information as a stand-alone manuscript, as material to be incorporated into an original research manuscript, or as search-able / filter-able data tables.


External datasets
If you want to expand your analysis beyond current datasets, or if you want to run an analysis on other datasets, we will track down those datasets and perform an analysis specific to your research aims. Sources may include: population demographic data; GEO, SRA, dbGap, EGA, and other archived sequence data repositories; or data from supplemental tables in published literature.
Toolshed Development
Tailored data presentation, statistical analysis, and interactive tools
Code Repositories
With regards to attaining funding, increased emphasis is currently placed on developing and maintaining a code repository. Contributions to bioinformatics sciences need to be demonstrated and open source designs are prized.
We can start a code repository for you, building scripts based on most frequent analyses performed in your research. This will be hosted online, with a custom domain (website) name for you to reference in any funding, progress report, or publication documentation. If you have code from past analysts or students, we can format and integrate that as well. But you don't need to supply anything! We can do it all for you.
Laboratory websites
It is often beneficial to have all research in one place and institutional profile provisions are not adequate for this.
We can design and launch a website based on your past and current research. Whether you are inducting new personnel, applying for funding, branching into the industrial sector, or just want to show-off some cool stuff, a website is a great resource. We can do everything for you, based on a few Specific Aims pages or published literature. At the conclusion of the project, we will transfer all ownership and walk you through how to make future changes. (Or, of course, we can maintain the site for you and update as needed.)
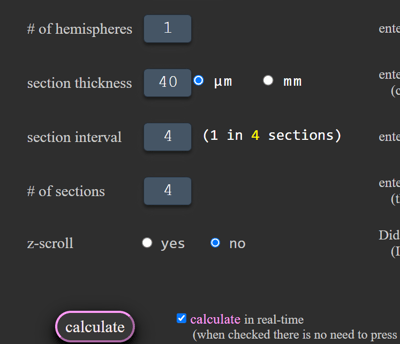
Calculators and Web Apps
Often in research the same computational tasks are performed repeatedly and computing by different personnel leaves room for variation and experimental error.
If you have a calculation, look-up, or other repetitive task that you would like to standardize, or just automate, we can design the tool for you. This will be implemented through a website and can be made public or private, depending on your desires.


Data Repositories
Long-standing projects and collaboration with other laboratories, often at other institutions geographically disperse, results in a mass of data spread over personal computers and storage devices, often with formatting idiosyncrasies.
We can make a web-based database to organize and increase utility of these datasets, fostering future collaboration and dissemination of findings among current and past project investigators. This can be publicly facing or an internal password-protected tool. However, having an outward-facing, accessible database can help express the breadth of a research initiative which can be hard to demonstrate when applying for future funding.
Non-neuroscience
We can, and do, work on non-neuroscience projects. Any of the bioinformatic services can be conducted on any biological science dataset and analytic services on any biological or social science dataset. If you have a non-neuroscience related request, we encourage you contact us and outline your need. The decision to target neuroscience research was made based on our observed need for experienced analysts and quick turn-arounds in this field; however, it does not limit projects we accept.

Maps
Maps are a great resource for comparing data that is geographically defined. Tools like choropleth maps also provide a colorful, flashy attraction for new visitors to your site and can help engage those uninitiated to your research.
We provide a variety of options for choropleth and geographical mapping. We can use government datasets (BRFSS, NNDSS, PLACES/500 cities, SDOH), or your own supplied data to make choropleths for your needs. These can be interactive graphs or flat panels for use in presentations and publications. We can also impose a t-axis to demonstrate movement and change over time, for example population migrations, pollution increases or decreases, government funding allocation, medication consumption and doctor compliance.


Statistics Explanation
Use of t-test, chi squares, correlations, percentage of, and fold-change are pervasive but not always properly understood.
If you need an explanation for any of these, or other processes, we can provide a formal lecture or an informal discussion based on your business needs and company size. Alternately, we can provide a report on the meaning of a statistical analysis and supplemental visualizations or fact-checking.

Dataset Cleaning (Cleansing)
Datasets are a mix of raw data and metadata, categories that can shift based on the type of insight you need. Often input for metadata is not standard and contains errors. This results in messy collections where collation or use can be unfeasible by the time you want to do something.
We can clean, collate, and prepare any type of data. Process may include:
Field standardization (collapsing of redundant fields, implementation of standardized formatting per field)
Handling missing values (masking of fields, imputation of missing data by bootstrap re-sampling or augmentation involving regression or machine learning, combination of fields)
Transformation (changing units of measurement, language conversion)
Data validation (examining the data and identifying likely errors from input, prior calculations, or file format changes)
Restructuring (generating a novel clean dataset based on the messy one(s))
Contact us for custom data analysis and visualization solutions.
Video or email consultations are free and project pricing is transparent.